
Tutorial de Big Data: ¡Todo lo que necesitas saber sobre Big Data!
Tutorial de Big Data
Big Data, ¿no has oído este término antes? Estoy seguro de que sí. En los últimos 4 a 5 años, todo el mundo habla de Big Data. Pero realmente sabes qué es exactamente este término “Big Data”, ¿cómo está teniendo un impacto en nuestras vidas y por qué las organizaciones están buscando profesionales con habilidades en el Big Data? En este Tutorial de Big Data, le daré una visión completa sobre lo que es el Big Data.
A continuación se presentan los temas que voy a tratar en este tutorial de Big Data:
- Historia del Big Data
- Factores de conducción de Big Data
- ¿Qué es Big Data?
- Características del Big Data
- Tipos de Big Data
- Ejemplos de Big Data
- Aplicaciones del Big Data
- Desafíos con el Big Data
Historia del Big Data
En la antigüedad, la gente solía viajar de un pueblo a otro pueblo en un carro impulsado por caballos, pero con el paso del tiempo, las aldeas se convirtieron en ciudades y la gente se extendió. La distancia para viajar de un pueblo a otro también aumentó. Por lo tanto, se convirtió en un problema para viajar entre las ciudades, junto con el equipaje. De repente, un tipo inteligente sugirió que deberíamos acicalar y alimentar más a un caballo para resolver este problema. Cuando miro esta solución, no es tan mala, pero ¿crees que un caballo puede convertirse en un elefante? No creo. Otro tipo inteligente dijo, en lugar de 1 caballo tirando del carro, vamos a tener 4 caballos para tirar del mismo carro. ¿Qué piensan de esta solución? Creo que es una solución fantástica. Ahora, la gente puede viajar grandes distancias en menos tiempo e incluso llevar más equipaje.
El mismo concepto se aplica en Big Data. Big Data dice que, hasta hoy, estábamos de acuerdo con el almacenamiento de los datos en nuestros servidores porque el volumen de los datos era bastante limitado, y la cantidad de tiempo para procesar estos datos también estaba bien. Pero ahora en este mundo tecnológico actual, los datos están creciendo demasiado rápido y la gente está confiando en los datos muchas veces. También la velocidad a la que los datos están creciendo, se está volviendo imposible almacenar los datos en cualquier servidor.
A través de este blog sobre tutorial de Big Data, vamos a explorar las fuentes de Big Data, que los sistemas tradicionales no están almacenando y procesando.
Factores de conducción de Big Data
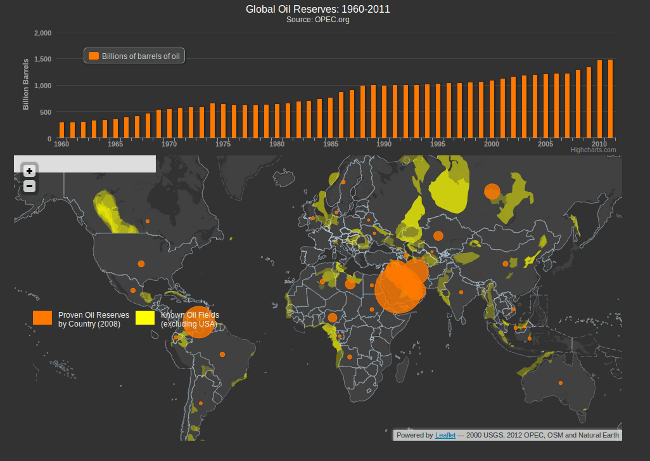
La cantidad de datos en el planeta Tierra está creciendo exponencialmente por muchas razones. Varias fuentes y nuestras actividades diarias generan muchos datos. Con la invención de la web, todo el mundo se ha puesto en línea, cada cosa que hacemos deja un rastro digital. Con los objetos inteligentes en línea, la tasa de crecimiento de datos ha aumentado rápidamente. Las principales fuentes de Big Data son los sitios de redes sociales, redes de sensores, imágenes digitales / videos, teléfonos celulares, registros de transacciones de compra, registros web, registros médicos, archivos, vigilancia militar, comercio electrónico, investigación científica compleja y así sucesivamente. Toda esta información equivale a unos bytes quintillones de datos. Para 2020, los volúmenes de datos rondarán los 40 Zettabytes, lo que equivale a añadir cada grano de arena del planeta multiplicado por setenta y cinco.
¿Qué es Big Data?
Big Data es un término utilizado para una colección de conjuntos de datos que son grandes y complejos, lo que es difícil de almacenar y procesar mediante herramientas de administración de bases de datos disponibles o aplicaciones de procesamiento de datos tradicionales. El desafío incluye la captura, curación, almacenamiento, búsqueda, uso compartido, transferencia, análisis y visualización de estos datos.
Características del Big Data
Las cinco características que definen big data son: Volumen, Velocidad, Variedad, Veracidad y Valor.
-
Volumen
El volumen se refiere a la “cantidad de datos”, que está creciendo día a día a un ritmo muy rápido. El tamaño de los datos generados por los seres humanos, las máquinas y sus interacciones en las redes sociales en sí es enorme. Los investigadores han pronosticado que 40 Zettabytes (40.000 Exabytes) se generarán en 2020, lo que supone un aumento de 300 veces con respecto a 2005.
-
Velocidad
La velocidad se define como el ritmo al que diferentes fuentes generan los datos cada día. Este flujo de datos es masivo y continuo. Hay 1.030 millones de usuarios activos diarios (Dau de Facebook) en el móvil a partir de ahora, lo que supone un aumento interanual del 22%. Esto muestra la rapidez con la que el número de usuarios está creciendo en las redes sociales y la rapidez con la que se generan los datos diariamente. Si usted es capaz de manejar la velocidad, usted será capaz de generar información y tomar decisiones basadas en datos en tiempo real.
-
Variedad
Como hay muchas fuentes que están contribuyendo al Big Data, el tipo de datos que están generando es diferente. Se puede estructurar, semiestructurar o desestructurar. Por lo tanto, hay una variedad de datos que se generan todos los días. Antes, solíamos obtener los datos de Excel y bases de datos, ahora los datos vienen en forma de imágenes, audios, videos, datos del sensor, etc. como se muestra en la imagen de abajo. Por lo tanto, esta variedad de datos no estructurados crea problemas en la captura, almacenamiento, minería de datos y análisis de los datos.
-
Veracidad
La veracidad se refiere a los datos en duda o incertidumbre de los datos disponibles debido a la inconsistencia e incompetencia de los datos. En la imagen siguiente, puede ver que faltan pocos valores en la tabla. Además, algunos valores son difíciles de aceptar, por ejemplo: 15000 valor mínimo en la 3ª fila, no es posible. Esta incoherencia e incompetencia es veracidad.
Los datos disponibles a veces pueden ser desordenados y tal vez difíciles de confiar. Con muchas formas de big data, la calidad y la precisión son difíciles de controlar como las publicaciones de Twitter con hashtags, abreviaturas, errores tipográficos y discurso coloquial. El volumen es a menudo la razón detrás de la falta de calidad y precisión en los datos.- Debido a la incertidumbre de los datos, 1 de cada 3 líderes empresariales no confía en la información que utilizan para tomar decisiones.
- En una encuesta se encontró que el 27% de los encuestados no estaba seguro de cuánto de sus datos eran inexactos.
- La mala calidad de los datos le cuesta a la economía estadounidense alrededor de 3,1 billones de dólares al año.
-
Valor
Después de discutir volumen, velocidad, variedad y veracidad, hay otra V que debe tenerse en cuenta al mirar big data es decir, valor. Está bien tener acceso al big data, pero a menos que podamos convertirlo en valor es inútil. Al convertirlo en valor me refiero a, ¿Se está sumando a los beneficios de las organizaciones que están analizando big data? ¿Está trabajando la organización en Big Data logrando un alto ROI (Retorno de la Inversión)? A menos que, se suma a sus ganancias trabajando en Big Data, es inútil.
Como se describe en Variety, hay diferentes tipos de datos que se generan todos los días. Por lo tanto, ahora entendamos los tipos de datos:
Tipos de Big Data
Big Data podría ser de tres tipos:
- Estructurado
- Semiestructurado
- Desestructurado
-
Estructurado
Los datos que se pueden almacenar y procesar en un formato fijo se denominan datos estructurados. Los datos almacenados en un sistema de administración de bases de datos relacionales (RDBMS) son un ejemplo de datos “estructurados”. Es fácil procesar datos estructurados, ya que tiene un esquema fijo. El lenguaje de consulta estructurado (SQL) se utiliza a menudo para administrar este tipo de datos.
-
Semiestructurado
Los datos semiestructurados son un tipo de datos que no tiene una estructura formal de un modelo de datos, es decir, una definición de tabla en un DBMS relacional, pero sin embargo tiene algunas propiedades organizativas como etiquetas y otros marcadores para separar elementos semánticos que facilitan el análisis. Los archivos XML o los documentos JSON son ejemplos de datos semiestructurados.
-
Desestructurado
Los datos que tienen forma desconocida y no se pueden almacenar en RDBMS y no se pueden analizar a menos que se transformen en un formato estructurado se denominan datos no estructurados. Archivos de texto y contenidos multimedia como imágenes, audios, vídeos son ejemplo de datos no estructurados. Los datos no estructurados están creciendo más rápido que otros, los expertos dicen que el 80 por ciento de los datos de una organización no están estructurados.
Hasta ahora, acabo de cubrir la introducción del Big Data. Además, este tutorial de Big Data habla de ejemplos, aplicaciones y desafíos en Big Data.














Comentarios
Los comentarios han sido cerrados